Introduction
Set up continuous integration and automate test pipelines with Concourse CI's composable declarative syntax. Compared to other systems for setting up continuous integration, the Concourse team makes every effort to simplify the management of the continuous integration pipeline.

The previous instructions looked at downloading and setting up Concourse on an Ubuntu 22.04 server and secured our web interface with SSL from a Let's Encrypt CA.
In this tutorial, we'll look at using Concourse to run tests automatically, and the changes will be committed to our repository.
Consider setting up a continuous integration pipeline using the "hello world" application, using the code Hapi.js, created on the Node.js web framework to ensure the process of code synchronization with assembly and testing. Let's add CI definitions to the product repository itself. Let's use the terminal and the "fly" utility to start the pipeline in Concourse. Finally, let's add the changes to our repository in order to save them and implement the tests in the CI workflow.
Preparation for work
Before you start, you need to run a server based on Ubuntu/Debian/CentOS, RAM must be at least 1 GB.
Set the user's permissions to execute with sudo.
Download and install the Concourse utility from the official site or from GitHub and the Nginx web server installed using the package manager. You need to set up a TLS/SSL security certificate, set up a reverse proxy server for the Concourse web interface.
We need to get a domain name that points to our Concourse server.
Use the following instructions for proper setup:
- Installing and configuring the server with a standard user;
- Install Concourse CI;
- Installing and configuring Nginx;
- Configuring Concourse CI Security with SSL;
In this manual, the entire process of work is considered on a working computer with pre-installed Ubuntu Linux. For this reason, you should make sure that you have installed various utilities for editing text files that are convenient for you to use.
You will also need the Git utility on your local computer and follow our instructions for proper configuration.
When we made sure that the Concourse server is running and that the local computer has all the tools for working with text files and Git is installed, let's proceed to the main task of our instructions.
Using Fly on the Command Line
You need to make sure that Concourse Worker and Fly are installed on the main server (to manage the pipeline using the command line).
For everyday work with Concourse CI, it is more convenient to install fly on a working computer, which has daily tools for working with the development of various products.
To get the latest version of fly, you need to open the Concourse CI web interface installed on the server:
https://server_urlAfter authorization in the server, in the lower right part of the screen, you can download fly by selecting your system at the workplace:

We click on the icon of our local system and download it to a directory convenient for us, in our case it is Downloads.
Linux and MacOS
If your main workstation has Linux or a device running MacOS, follow these steps to install and run Fly:
chmod +x /root/flyNext, you need to add the fly utility to the "PATH" environment to run it in the terminal:
install /root/fly /usr/local/binLet's run the fly utility and get version information:
fly –versionWe get a result that matches the version from the web interface:
7.9.0Windows
If the primary system is a Windows workstation, you need to run PowerShell and add the bin directory:
PS C:\Users\Serverspace> mkdir binYou need to copy the downloaded fly.exe utility to the bin directory:
PS C:\Users\Serverspace> mv .\Downloads\fly.exe .\bin\Let's check the relevance of the profile by running the command:
PS C:\Users\Serverspace> Test-Path $profileIf the result is True, the current profile is available in the system.
If the result is False, you need to create a new profile:
PS C:\Users\Serverspace> New-Item -path $profile -type file -forceAs a result, we get:
Directory: C:\Users\Serverspace\Documents\WindowsPowerShell
Mode LastWriteTime Length Name
---- ------------- --------- ----
-a---- 31.01.2023 18:05 0 Microsoft.PowerShell_profile.ps1Let's open the created Notepad text editor profile file:
PS C:\Users\Serverspace> notepad.exe $profileA new text file editor window will open and add to the PATH environment and specify the path to the file:
$env:path += ";C:\Users\Serverspace\bin"Save the file and exit.
Let's start reading the path from $profile:
PS C:\Users\Serverspace> . $profileNext, run the command to check the version of the downloaded fly file:
PS C:\Users\Serverspace> fly.exe –versionAs an output, we get:
7.9.0When executing commands from Windows, you need to change every fly command (in this tutorial) to fly.exe.
Authorization using the command line
After successfully launching fly, you need to log in to the installed Concourse, each server can use several "targets", with which you can identify the necessary pipeline in the system and execute commands in it.
In this tutorial, let's take a look at the tutorial in the target name of the Concourse system:
fly -t tutorial login -c https://concourse_server_urlIt is necessary to fill in the login and password from the configuration file /etc/concourse/web_environment of our server.
As a result, we get:
logging in to team 'main'
username: serverspace
password:target saved
If authorization is successful, a .flyrc file will appear in your home directory.
Let's check the creation of "tutorial" in .flyrc:
fly -t tutorial syncAs a result, we get:
version 7.9.0 already matches; skippingForking and Cloning a Repository
After setting up fly, you need to set up the repository to use the Concourse pipelines.
In a web browser, open the link to the repository, which we will use in our instructions.
In Concourse, you need to add a continuous integration pipeline to the main repository branch.

In the terminal, go to the user directory. Let's make a copy of the repository on our working computer, for this we will use the following commands of the git clone utility and go to a new branch:
cd
git clone https://github.com/githubUser/hello_hapi
cd hello_hapi
git checkout -b pipelineAfter executing the commands, we get the following line:
Switched to a new branch 'pipeline'We have switched to a new branch.
Set up continuous integration for an application
Let's define our files that are associated with the project repository. Thus, we will ensure the synchronization of the work of continuous integration with the code under test.
The test suite is located in the test directory. It contains three tests. The test script resides in package.json, which stores the test element in the scripts object.
It is necessary to create a directory called ci and define two subfolders named tasks and scripts in it, and we will place the product continuous integration files in them.
Let's execute the following command:
mkdir -p ci/{tasks,scripts}Adding a pipeline
In the ci directory, we will create a file called pipeline.yml, in which we will specify our configuration settings:
vim ci/pipeline.ymlAfter creating the configuration file for the main pipeline, we need to add our configuration to it.
Definition for NPM Cache
Let's add the following configuration:
---
resource_types:
- name: npm-cache
type: docker-image
source:
repository: ymedlop/npm-cache-resource
tag: latestThe processes that decouple from the continuous integration data are processed by Concourse and extract the abstraction status information and they are converted into resources.
Resources are source data for Concourse to use when receiving or sending information.
The resource_types string will define new resource types that you can implement in your pipeline.
Defining and caching a repository
Add the following piece of code to pipeline.yml to define the actual resource for the pipeline:
resources:
- name: hello_hapi
type: git
source: &repo-source
uri: https://github.com/githubUser/hello_hapi
branch: master
- name: dependency-cache
type: npm-cache
source:
<<: *repo-source
paths:
- package.jsonThe first of the resources defines our branch from the repository. Source defines the binding YAML for the repo-source name.
The first resource shows our repository branch from GitHub.
The second resource defines a "cache-dependency" which will use the resource type «npm-cache» and determine to perform the download of the necessary dependencies of the project.
The string "source" is followed by <<: *repo-source is used to redirect and expand items. At the end we write "paths", which refers to the previously downloaded package.json package.
Dependency Testing
Let's define the actual continuous integration processes using the Concourse jobs. At the end of the pipeline.yml configuration, add the following piece of code without deleting the previous lines of code:
jobs:
- name: install_dependencies
plan:
- get: hello_hapi
trigger: true
- get: dependency-cache
- name: run_tests
plan:
- get: hello_hapi
trigger: true
passed: [install_dependencies]
- get: dependency-cache
passed: [install_dependencies]
- task: run_the_test_suite
file: hello_hapi/ci/tasks/run_tests.ymlThe code will implement two jobs. Each task contains a name and a plan. The plan stores elements such as "receiving" and "setting". The first of the get statements retrieves data from the repository and sets the trigger parameter to true.
The second Get (dependency-cache) includes a specific resource to download and cache the necessary Node.js dependencies in the project.
The Get operator needs to evaluate the requirements from package.json and based on this, the operator loads the data.
There is also a "passed" statement in the code, which assigns to the get statement those elements that have passed the previous steps with a successful result, in order to tie together pipelined processes.
At the end of all statements, a line is formed with a link to "run_tests.yml", for extracting and executing testing. The next step is to create this file.
Creation of test tasks
The task extraction process will help you keep your pipeline definition concise and easy to read.
You need to create a new configuration file in the ci/tasks directory called run_tests.yml:
vim ci/tasks/run_tests.ymlTo transfer test tasks, it is necessary to fill in the line with the platform according to our system in which the developer's work process is performed, we also indicate the image that any input or output can define for use in the task. At the end, specify the path to the executable file.
Add the following piece of code to set up a task for testing:
---
platform: linux
image_resource:
type: docker-image
source:
repository: node
tag: latest
inputs:
- name: hello_hapi
- name: dependency-cache
run:
path: hello_hapi/ci/scripts/run_tests.sh
The run_tests.yml file contains the tasks that will be run on Linux. Concourse satisfies the above lines of code without any additional configuration.
You must specify an image to use "worker" when running tasks. However, we will be able to create custom image types and use them. The most commonly used is the most famous Docker image.
Since our repository consists of a Node.js application, we'll select the "node" image when running our tests because it has all the necessary tools.
For Concourse, you can define entry and exit for tasks to specify the resources that can be used to access the artifacts they will create.
The resources must match the inputs retrieved earlier at the "job" level. This makes all of these resources available to the task environment as a top-level directory that can be manipulated during task execution.
In this manual, we consider an application that is located in the previously downloaded hello_hapi directory. Node.js dependencies are stored in the dependency-cache directory.
The stage of running a script with a script sometimes requires moving files or directories to the expected location that is specified in the script and placing artifacts in output locations at the end of tasks.
The script contains the command to be executed. Each task stores one command with an argument, so let's create a bash script to run the commands. But, often the path to the file with the command script is indicated in the task. In our case, we specify the path to the script in the hello_hapi directory, which is located in hello_hapi/ci/scripts/run_tests.sh.
In the next step, consider creating a script file.
You need to save and exit.
Creating a script file
Now we need to create a script file that runs our tests. You will need to make changes using a text editor.
touch ci/scripts/run_tests.sh
vim ci/scripts/run_tests.shThis script will contain data for the testing environment and moving elements to the desired directory. Next, the tests from the specified repositories will run and npm test will run.
Use the following code to run tests:
#!/usr/bin/env bash
set -e -u -x
mv dependency-cache/node_modules hello_hapi
cd hello_hapi && npm test
Exit and save using :wq!
First of all, the path to the command interpreter is indicated for running commands from this file. Let's set the default parameters to stop the script when errors are found and in variables. Thus, the script is executed in a safe way and we get a good visibility of debugging.
Mv (move) moves cache dependencies from node_modules to hello_hapi's home directory.
Next, go to the project's home directory and run npm test.
When you have written the code in a file, you must save and exit.
You need to assign permissions to run run_tests.sh from the ci/scripts directory:
chmod +x ci/scripts/run_tests.shAfter assigning rights, our pipeline is ready to run.
Running a pipeline in Concourse
Before we merge the pipeline branch into the main branch and export it to GitHub, we need to go ahead and upload the pipeline to Concourse. It also processes our repository to detect changes and runs a continuous integration routine when detected.
You must manually start the pipeline using the commands of the previously downloaded fly utility.
We specify the target through the -t parameter, add a pipeline, and after the -p parameter, enter the name and use -c to point to the file from which our pipeline data will be retrieved:
fly -t tutorial set-pipeline -p hello_hapi -c ci/pipeline.ymlWe agree to launch:
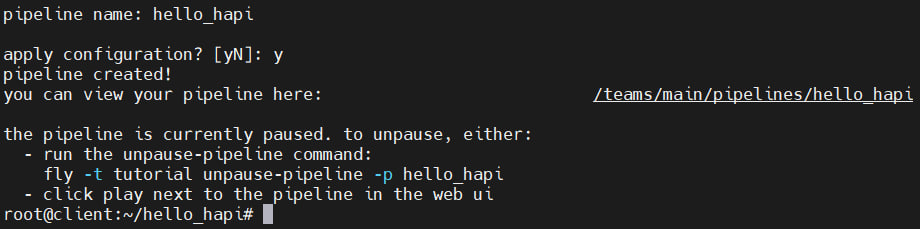
After successfully adding a pipeline, it is paused. Resuming work occurs through the Web interface or by executing the command:
fly -t tutorial unpause-pipeline -p hello_hapi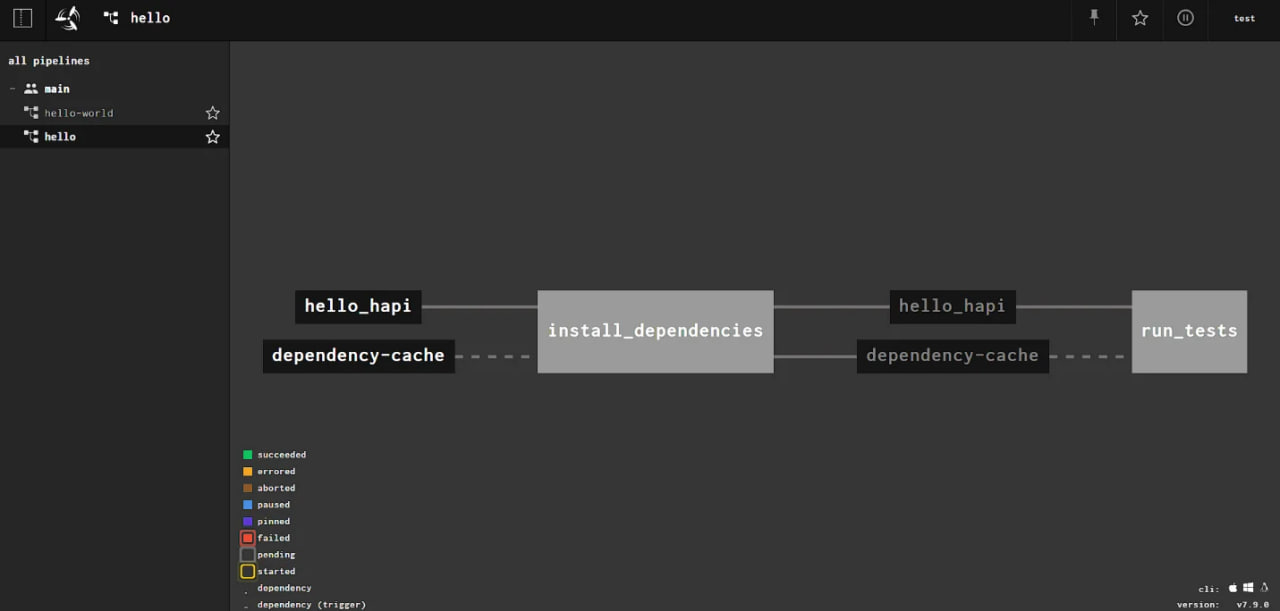
Also in the Web interface, you can use the button to start the pipeline.
Committing changes in Git
After starting the continuous integration process, we need to add changes to our Git repository.
Adding the ci directory to git:
git add ciYou need to check the status of the added files:
git status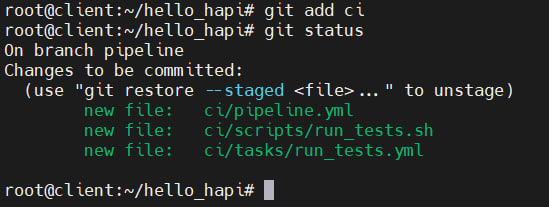
Let's commit the changes and use the command:
git commit -m 'First commit for our project'We need to merge our branches by switching to the master branch.
git checkout master
git merge pipeline
We need to commit the changes we made to our repository:
git push origin masterIt is worth noting that after saving all the changes, you need to run the test in one minute.
Test Run View
Returning to the Web interface, you need to start a new test by clicking on the + button:
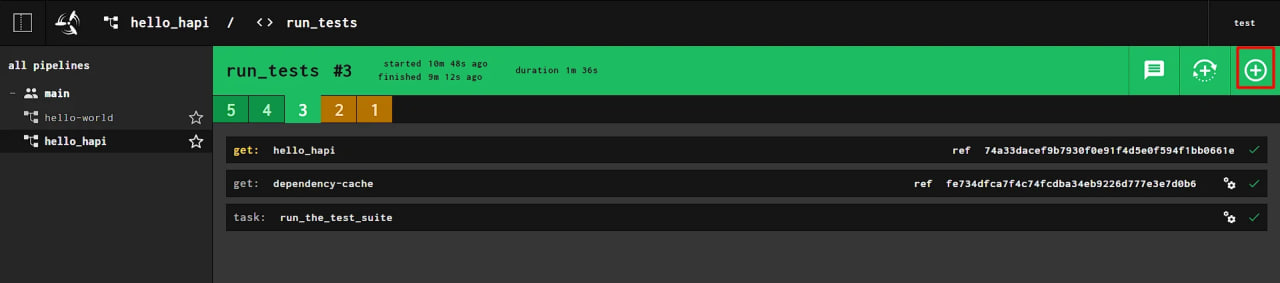
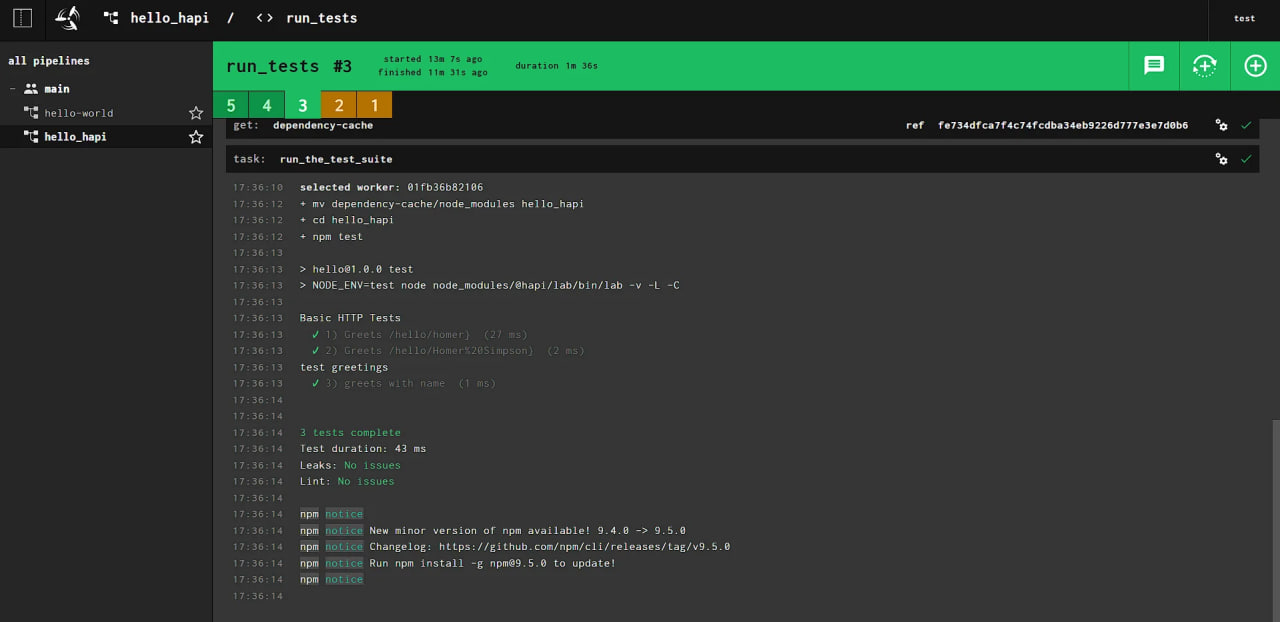
The first two tests are marked in yellow because they did not interact with the Git repository. After adding new tests, you can click on the task (tasks) and see the test results.
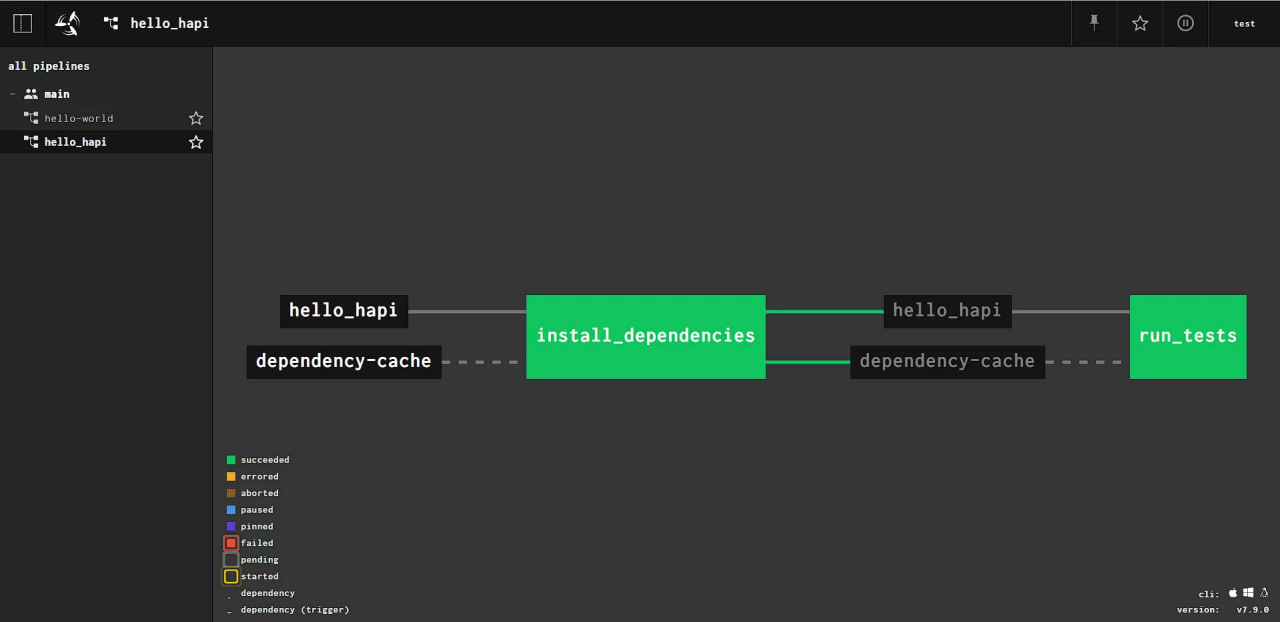
If you click on the inscription hello_hapi, you can return to the initial state of the pipeline and see the result of running the pipeline:
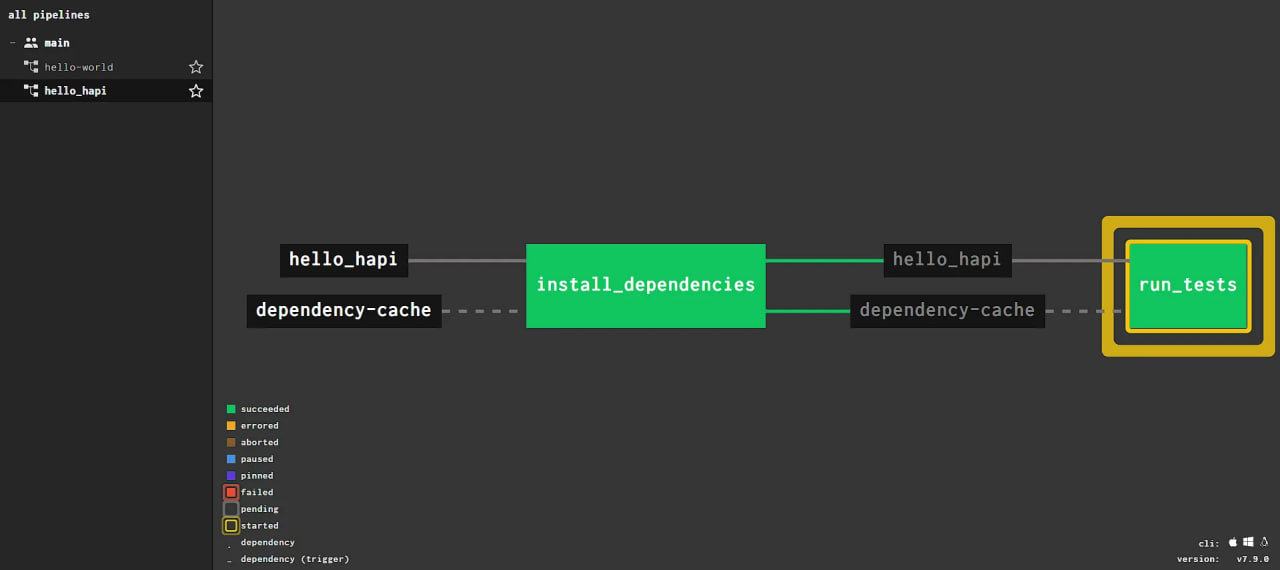
Yellow squares around a task means that a new task is being started:
Conclusions
In this guide, we covered:
- setting up the fly utility;
- cloning a repository from Git;
- creation of a script for the conveyor;
- creation of a script for tests;
- starting the conveyor;
- making changes to our repository;
- running tests.


